目录
简介
简而言之,实现 MVCC 的 DBMS 在内部维持着单个逻辑数据的多个物理版本,当事务修改某数据时,DBMS 将为其创建一个新的版本;当事务读取某数据时,它将读到该数据在事务开始时刻之前的最新版本。
MVCC 首次被提出是在 1978 年的一篇 MIT 的博士论文中。在 80 年代早期,DEC 的 Rdb/VMS 和 InterBase 首次真正实现了 MVCC,其作者是 Jim Starkey,NuoDB 的联合创始人。如今,Rdb/VMS 成了 Oracle Rdb,InterBase 成为开源项目 Firebird。
MVCC
MVCC 的核心优势可以总结为以下两句话:
Writers don't block readers.
写不阻塞读
Readers don't block writers.
读不阻塞写
只读事务无需加锁就可以读取数据库某一时刻的快照,如果保留数据的所有历史版本,DBMS 甚至能够支持读取任意历史版本的数据,即 time-travel。
Design Decisions
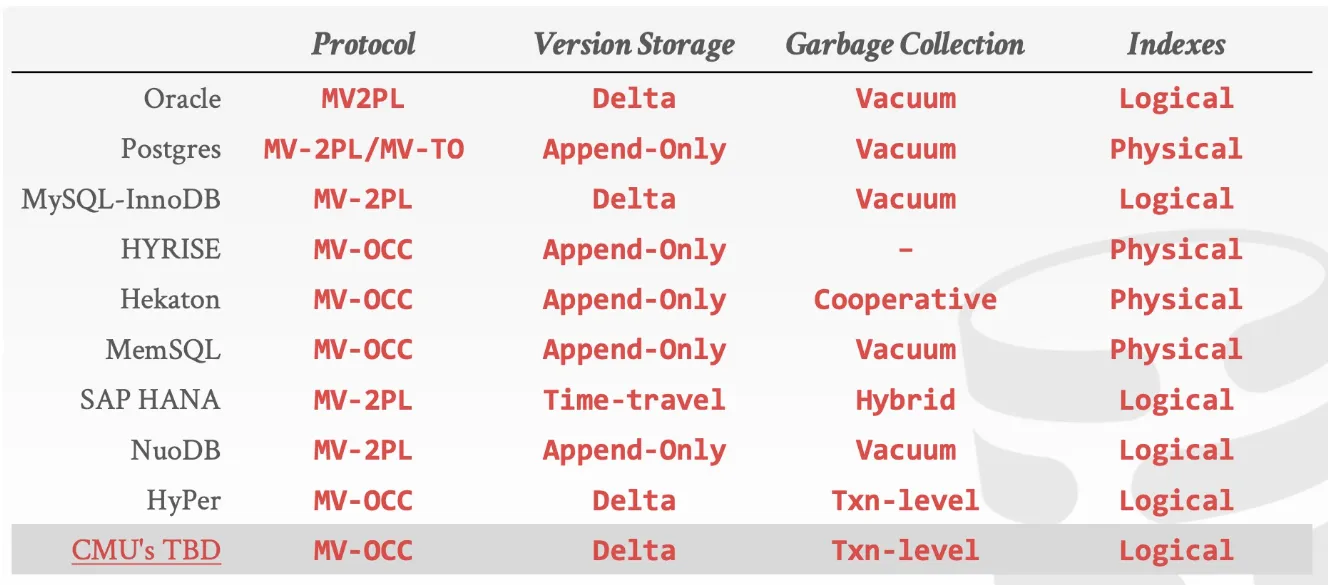
上文提到,MVCC 不止是一个并发控制协议,它由许多部分组成,这些部分包括:
- Concurrency Control Protocol
- Version Storage
- Garbage Collection
- Index Management 每一部分都可以选择不同的方案,可以根据具体场景作出最优的设计选择。
Concurrency Control Protocol
前面 2 节课已经介绍了各种并发控制协议,MVCC 可以选择其中任意一个:
- Approach #1:Timestamp Ordering (T/O):为每个事务赋予时间戳,并用以决定执行顺序
- Approach #2:Optimistic Concurrency Control (OCC):为每个事务创建 private workspace,并将事务分为 read, write 和 validate 3 个阶段处理
- Approach #3:Two-Phase Locking (2PL):按照 2PL 的约定获取和释放锁
Version Storage
如何存储一条数据的多个版本?DBMS 通常会在每条数据上拉一条版本链表 (version chain),所有相关的索引都会指到这个链表的 head,DBMS 可以利用它找到一个事务应该访问到的版本。不同的版本存储方案在 version chain 上存储的数据不同,主要有 3 种存储方案:
- Approach #1:Append-Only Storage:新版本通过追加的方式存储在同一张表中
- Approach #2:Time-Travel Storage:老版本被复制到单独的一张表中
- Approach #3:Delta Storage:老版本数据的被修改的字段值被复制到一张单独的增量表 (delta record space) 中
Garbage Collection
随着时间的推移,DBMS 中数据的旧版本可能不再会被用到,如:
- 已经没有活跃的事务需要看到该版本
- 该版本是被一个已经中止的事务创建
这时候 DBMS 需要删除这些可以回收的物理版本,这个过程也被称为 GC。在 GC 的过程中,还有两个附加设计决定:
- 如何查找过期的数据版本
- 如何确定某版本数据是否可以被安全回收
GC 可以从两个角度出发:
- Approach #1:Tuple-level:直接检查每条数据的旧版本数据
- Approach #2:Transaction-level:每个事务负责跟踪数据的旧版本,DBMS 不需要亲自检查单条数据
Index Management
Primary Key Index
- 主键索引直接指向 version chain 的头部。
- Secondary Indexes 二级索引有两种方式指向数据本身:
- Approach #1:逻辑指针,即存储主键值或 Tuple Id
- Approach #2:物理指针,即存储指向 version chain 头部的指针
本文作者:yowayimono
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!