请注意,本文编写于 621 天前,最后修改于 620 天前,其中某些信息可能已经过时。
目录
bolt是个简单的kv嵌入式数据库,同sqlite是一样的定位,boltdb开启一个数据库的时候,一样也是新建一个.db文件,文件里的数据按page来组织,一个数据库又分为bucket来组织数据(类似于表)。
- bolt使用B+树来索引数据,一个bucket对应一棵树
- bolt使用mmap来直接映射db文件
- bolt支持subbucket
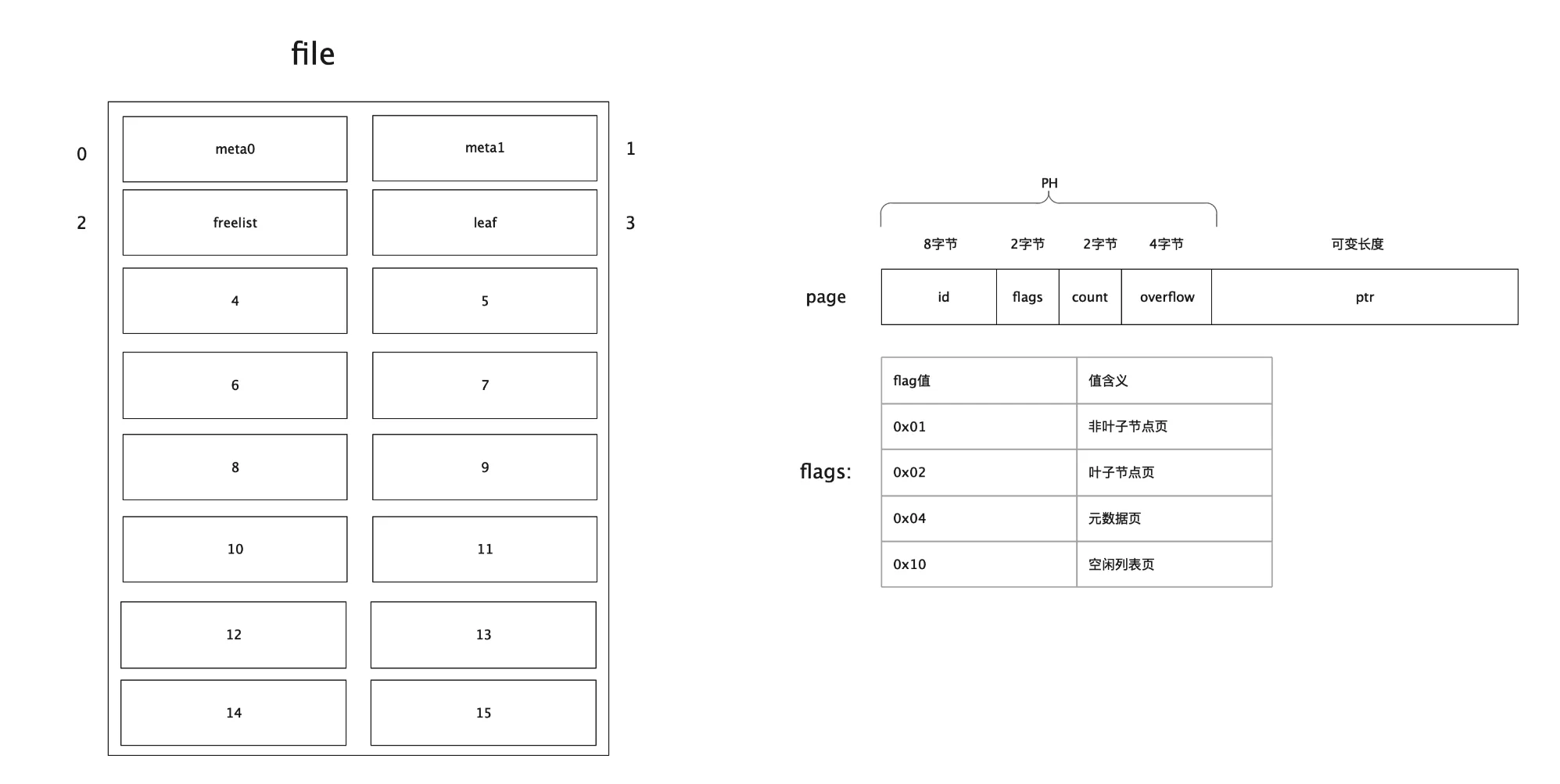
Page结构
bolt按页来读取和写入数据,一页大小为4k,一个页结构分为页头和真实数据,所有的数据在磁盘上都是按照页(page)来存储的
gotype pgid uint64
type page struct {
// 页id 8字节
id pgid
// flags:页类型,可以是分支,叶子节点,元信息,空闲列表 2字节,该值的取值详细参见下面描述
flags uint16
// 个数 2字节,统计叶子节点、非叶子节点、空闲列表页的个数
count uint16
// 4字节,数据是否有溢出,主要在空闲列表上有用
overflow uint32
// 真实的数据
ptr uintptr
}
Page Type
bolt将页分为以下类型组织起来,用常量来描述
- 分支节点页 branchPageFlag 0x01 存储索引信息(页号、元素key值)
- 叶子节点页 leafPageFlag 0x02 存储数据信息(页号、插入的key值、插入的value值)
- 元数据页 metaPageFlag 0x04 存储数据库的元信息,例如空闲列表页id、放置桶的根页等
- 空闲列表页 freelistPageFlag 0x10 存储哪些页是空闲页,可以用来后续分配空间时,优先考虑分配
go// 页头的大小:16字节
const pageHeaderSize = int(unsafe.Offsetof(((*page)(nil)).ptr))
const minKeysPerPage = 2
//分支节点页中每个元素所占的大小
const branchPageElementSize = int(unsafe.Sizeof(branchPageElement{}))
//叶子节点页中每个元素所占的大小
const leafPageElementSize = int(unsafe.Sizeof(leafPageElement{}))
const (
branchPageFlag = 0x01 //分支节点页类型
leafPageFlag = 0x02 //叶子节点页类型
metaPageFlag = 0x04 //元数据页类型
freelistPageFlag = 0x10 //空闲列表页类型
)
// typ returns a human readable page type string used for debugging.
func (p *page) typ() string {
if (p.flags & branchPageFlag) != 0 {
return "branch"
} else if (p.flags & leafPageFlag) != 0 {
return "leaf"
} else if (p.flags & metaPageFlag) != 0 {
return "meta"
} else if (p.flags & freelistPageFlag) != 0 {
return "freelist"
}
return fmt.Sprintf("unknown<%02x>", p.flags)
}
所有的page都有type方法
mate page
go// meta returns a pointer to the metadata section of the page.
func (p *page) meta() *meta {
// 将p.ptr转为meta信息
return (*meta)(unsafe.Pointer(&p.ptr))
}
type meta struct {
magic uint32 //魔数
version uint32 //版本
pageSize uint32 //page页的大小,该值和操作系统默认的页大小保持一致
flags uint32 //保留值,目前貌似还没用到
root bucket //所有小柜子bucket的根
freelist pgid //空闲列表页的id
pgid pgid //元数据页的id
txid txid //最大的事务id
checksum uint64 //用作校验的校验和
}
元数据的组织方式

freelist
go// freelist represents a list of all pages that are available for allocation.
// It also tracks pages that have been freed but are still in use by open transactions.
type freelist struct {
// 已经可以被分配的空闲页
ids []pgid // all free and available free page ids.
// 将来很快能被释放的空闲页,部分事务可能在读或者写
pending map[txid][]pgid // mapping of soon-to-be free page ids by tx.
cache map[pgid]bool // fast lookup of all free and pending page ids.
}
// newFreelist returns an empty, initialized freelist.
func newFreelist() *freelist {
return &freelist{
pending: make(map[txid][]pgid),
cache: make(map[pgid]bool),
}
}

将空闲列表转换成页信息,写到磁盘中,此处需要注意一个问题,页头中的count字段是一个uint16,占两个字节,其最大可以表示2^16 即65536个数字,当空闲页的个数超过65535时时,需要将p.ptr中的第一个字节用来存储其空闲页的个数,同时将p.count设置为0xFFFF。否则不超过的情况下,直接用count来表示其空闲页的个数
freelist->page
go// write writes the page ids onto a freelist page. All free and pending ids are
// saved to disk since in the event of a program crash, all pending ids will
// become free.
//将 freelist信息写入到p中
func (f *freelist) write(p *page) error {
// Combine the old free pgids and pgids waiting on an open transaction.
// Update the header flag.
// 设置页头中的页类型标识
p.flags |= freelistPageFlag
// The page.count can only hold up to 64k elements so if we overflow that
// number then we handle it by putting the size in the first element.
lenids := f.count()
if lenids == 0 {
p.count = uint16(lenids)
} else if lenids < 0xFFFF {
p.count = uint16(lenids)
// 拷贝到page的ptr中
f.copyall(((*[maxAllocSize]pgid)(unsafe.Pointer(&p.ptr)))[:])
} else {
// 有溢出的情况下,后面第一个元素放置其长度,然后再存放所有的pgid列表
p.count = 0xFFFF
((*[maxAllocSize]pgid)(unsafe.Pointer(&p.ptr)))[0] = pgid(lenids)
// 从第一个元素位置拷贝
f.copyall(((*[maxAllocSize]pgid)(unsafe.Pointer(&p.ptr)))[1:])
}
return nil
}
// copyall copies into dst a list of all free ids and all pending ids in one sorted list.
// f.count returns the minimum length required for dst.
func (f *freelist) copyall(dst []pgid) {
// 首先把pending状态的页放到一个数组中,并使其有序
m := make(pgids, 0, f.pending_count())
for _, list := range f.pending {
m = append(m, list...)
}
sort.Sort(m)
// 合并两个有序的列表,最后结果输出到dst中
mergepgids(dst, f.ids, m)
}
// mergepgids copies the sorted union of a and b into dst.
// If dst is too small, it panics.
// 将a和b按照有序合并成到dst中,a和b有序
func mergepgids(dst, a, b pgids) {
if len(dst) < len(a)+len(b) {
panic(fmt.Errorf("mergepgids bad len %d < %d + %d", len(dst), len(a), len(b)))
}
// Copy in the opposite slice if one is nil.
if len(a) == 0 {
copy(dst, b)
return
}
if len(b) == 0 {
copy(dst, a)
return
}
// Merged will hold all elements from both lists.
merged := dst[:0]
// Assign lead to the slice with a lower starting value, follow to the higher value.
lead, follow := a, b
if b[0] < a[0] {
lead, follow = b, a
}
// Continue while there are elements in the lead.
for len(lead) > 0 {
// Merge largest prefix of lead that is ahead of follow[0].
n := sort.Search(len(lead), func(i int) bool { return lead[i] > follow[0] })
merged = append(merged, lead[:n]...)
if n >= len(lead) {
break
}
// Swap lead and follow.
lead, follow = follow, lead[n:]
}
// Append what's left in follow.
_ = append(merged, follow...)
}
allocate
go// allocate returns the starting page id of a contiguous list of pages of a given size.
// If a contiguous block cannot be found then 0 is returned.
// [5,6,7,13,14,15,16,18,19,20,31,32]
// 开始分配一段连续的n个页。其中返回值为初始的页id。如果无法分配,则返回0即可
func (f *freelist) allocate(n int) pgid {
if len(f.ids) == 0 {
return 0
}
var initial, previd pgid
for i, id := range f.ids {
if id <= 1 {
panic(fmt.Sprintf("invalid page allocation: %d", id))
}
// Reset initial page if this is not contiguous.
// id-previd != 1 来判断是否连续
if previd == 0 || id-previd != 1 {
// 第一次不连续时记录一下第一个位置
initial = id
}
// If we found a contiguous block then remove it and return it.
// 找到了连续的块,然后将其返回即可
if (id-initial)+1 == pgid(n) {
// If we're allocating off the beginning then take the fast path
// and just adjust the existing slice. This will use extra memory
// temporarily but the append() in free() will realloc the slice
// as is necessary.
if (i + 1) == n {
// 找到的是前n个连续的空间
f.ids = f.ids[i+1:]
} else {
copy(f.ids[i-n+1:], f.ids[i+1:])
f.ids = f.ids[:len(f.ids)-n]
}
// Remove from the free cache.
// 同时更新缓存
for i := pgid(0); i < pgid(n); i++ {
delete(f.cache, initial+i)
}
return initial
}
previd = id
}
return 0
}
本文作者:yowayimono
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录