目录
最近有点忙,在忙一个比赛的事情,折腾k8s然后部署,还有开发,写了170左右的接口,一直在排练润色ppt,大一的时候看不起这些比赛,现在开始找工作了才知道确实很重要,以后还是得注意,今天给集群装上了kuboard,把所有pod都迁移到项目生产环境,itakeaway
还有im服务没有部署,今天完成吧,还得学N2,快考试了
这个集群管理工具确实好,但是别人的终究是黑盒,终究还是得去了解底层原理才对,进一步熟悉k8s,但是没那么多机器,现在用的是一台导师的ubuntu服务器,一台是我自己买的二手e5 2666v3,也是ubuntu,天天跑着,两台机器组成一个简单的集群
部署方案
首先介绍一下iTakeaway的部署方案,主要有两套部署方案,包括测试开发环境还有生产环境,生产环境主要是k8s进行管理,主要是稳定,后面会说
测试开发环境
主要是本地服务器 + docker +frp
采用frp主要是为了轻量,转发一下流量,因为开发环境一直是单机。只有保证应用完全没问题,一个开发阶段结束,测试过后才打包镜像上传,后续也会在k8s的test命名空间再进行测试
这样的方式方便快速验证想法,快速和前端对接,为什么不直接到本地?需要docker?因为前端不是我一个人负责,需要远程前后端对接口,遂做了端口转发。开发完只需要一个shell脚本就能更新代码,很方便。
生产环境
生产环境就主要是在k8s itakeaway命名空间了,我们利用校园网这个免费的局域网,搭建了自己的k8s集群,进行本地私有化部署,其实现在主要也是在测试,自动扩展,滚动更新这些先测试好,后续再部署网关,然后真正的部署到生产环境
有人会问,为什么要有两套方案,第一套是为了快速对接,k8s方案肯定是为了保证高可用了
大模型的探索
前段时间给iTakeaway开发了一个官网,还有包括商家app,用户app,后台管理系统,对接,很多事情,现在大概是能用了。
iTakeaway最大的特色,就是深度结合了大模型,我们利用的阿里云的qwen大模型,因为本身中文能力很好,综合能力也很棒,不需要在进行中文能力微调,而且我发现很多基于llama2/3微调出来的llama-chinese中文能力也很堪忧,可能用的数据集不怎么样,但是我们利用AI也制作了关于健康饮食方面数据集,数据量不大,效果不知道好不好,调参没调好
智能推荐
上面说我们深度结合了大模型,有哪些方面呢,首先是智能推荐,iTakeaway 1.0版本的推荐算法,主要是基于协同过滤,用的python算法包,给予物品的推荐,效果有一些,但是我们都是假数据,数据量小,所以不明显
再接入了大模型之后,我们转变了想法,竟然大模型有这么棒的生成能力,我们能否利用这种能力来做推荐呢?
主要思路是这样,首先分清楚推荐的场景,主要有以下
- 用户点开一个外卖餐品,推荐服务进行一个及时推荐
- 平台分析用户近期点餐食物营养数据,结合用户身体数据,推荐营养餐品
第一种主要是搭建复杂的推荐服务系统,说实话靠我一个人很难做到,但是第二种,我们有可能,利用大模型,我们可以收集用户近期点餐食品营养成分,结合用户身体状况进行推荐,怎么做到的呢?
主要流程有下
我们只收集一个星期内用户的信息,这个信息存到redis,设置一星期过期时间,当用户每天上线,就会触发健康推荐场景的推送了,后台在redis拿到信息通过http远程调用推荐服务接口,通过langchain,用prompt来实现
大概如下
当前用户近七天的营养数据如下,卡路里 xxx,糖分 xxx ,维生素 xxx .... 用户身体状况,体重,xxx,身高 xxx,年龄 xxx,是否患病,什么病 用户想要达到的目标,愿景 请你按照上面的用户信息和近期营养摄入和用户目标,推荐用户应该补充哪些营养,并推荐一些食物 记住,不要提及平台相关,不要回答,是的,直接给出问题就可以,回答格式,应该补充的营养,食物名,不要有过多的话语 ,例如,你最近需要补充维生素c,芹菜 {output}
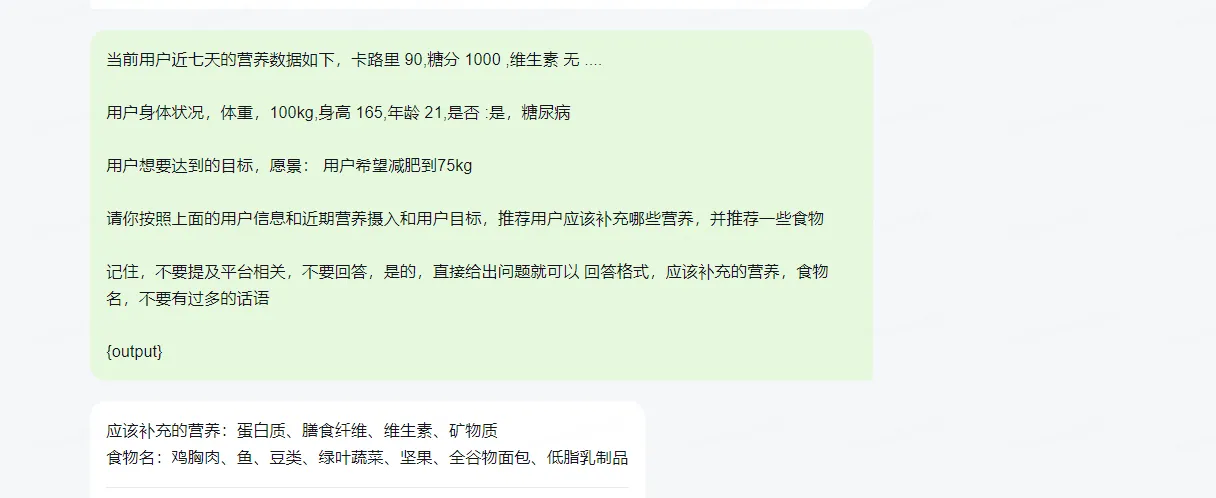
我们也可以尝试更换更好的提示模板,这样会提高效果,尽管如此,效果已经很好
图像识别
我们开始思考,iTakeaway是一个构建在健康理念的平台,号称可以获取用户最近营养摄入,有些问题,用户每天都在iTakeaway点餐?一日三餐都是?好像不太现实,所以我们有,用餐时间给用户提醒拍照,或用户自觉拍照上传,后台分析出营养成分并摄入
按照传统的思路,我们得有个营养数据库,存储的菜名和营养成分,然后需要一个模型来识别菜名,一般传统思维,我们会引入机器视觉来完成这个任务,我们也是这样的思路,可是这样的一个模型对我们来说太复杂了,数据量很大,有几千万 所需要的计算资源是巨量的
所以必须得换个思路,换呗
不试不知道,一试吓一跳

这玩意儿拥有让人惊叹的识别能力,准确率高达100%(不可靠测试),经过简单的prompt
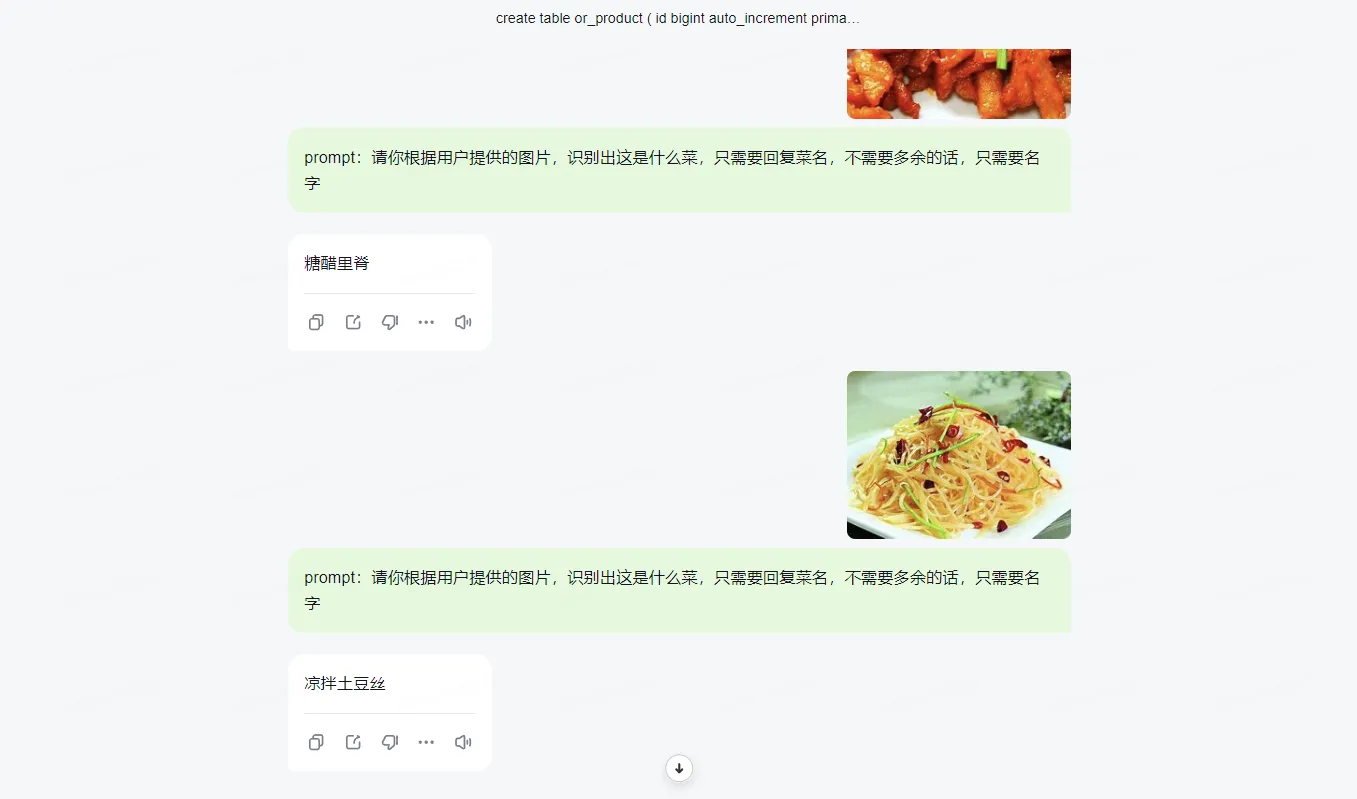
效果真好!
所以,我们需要的仅仅是一个多模态的大模型!
本文作者:yowayimono
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!