请注意,本文编写于 674 天前,最后修改于 674 天前,其中某些信息可能已经过时。
目录


sql
-- 建表语句
CREATE TABLE Employee (
id INT PRIMARY KEY,
name VARCHAR(50),
department VARCHAR(50),
managerId INT
);
-- 插入语句
-- 学习
INSERT INTO Employee (id, name, department, managerId) VALUES
(101, 'John', 'A', NULL),
(102, 'Dan', 'A', 101),
(103, 'James', 'A', 101),
(104, 'Amy', 'A', 101),
(105, 'Anne', 'A', 101),
(106, 'Ron', 'B', 101);
select e1.name from Employee as e1,
(select managerId from Employee group by managerId
having count(*)>=5)
as e2 where e1.id=e2.managerId;
select managerId as id from Employee group by
managerId having count(*)>=5;
自连接
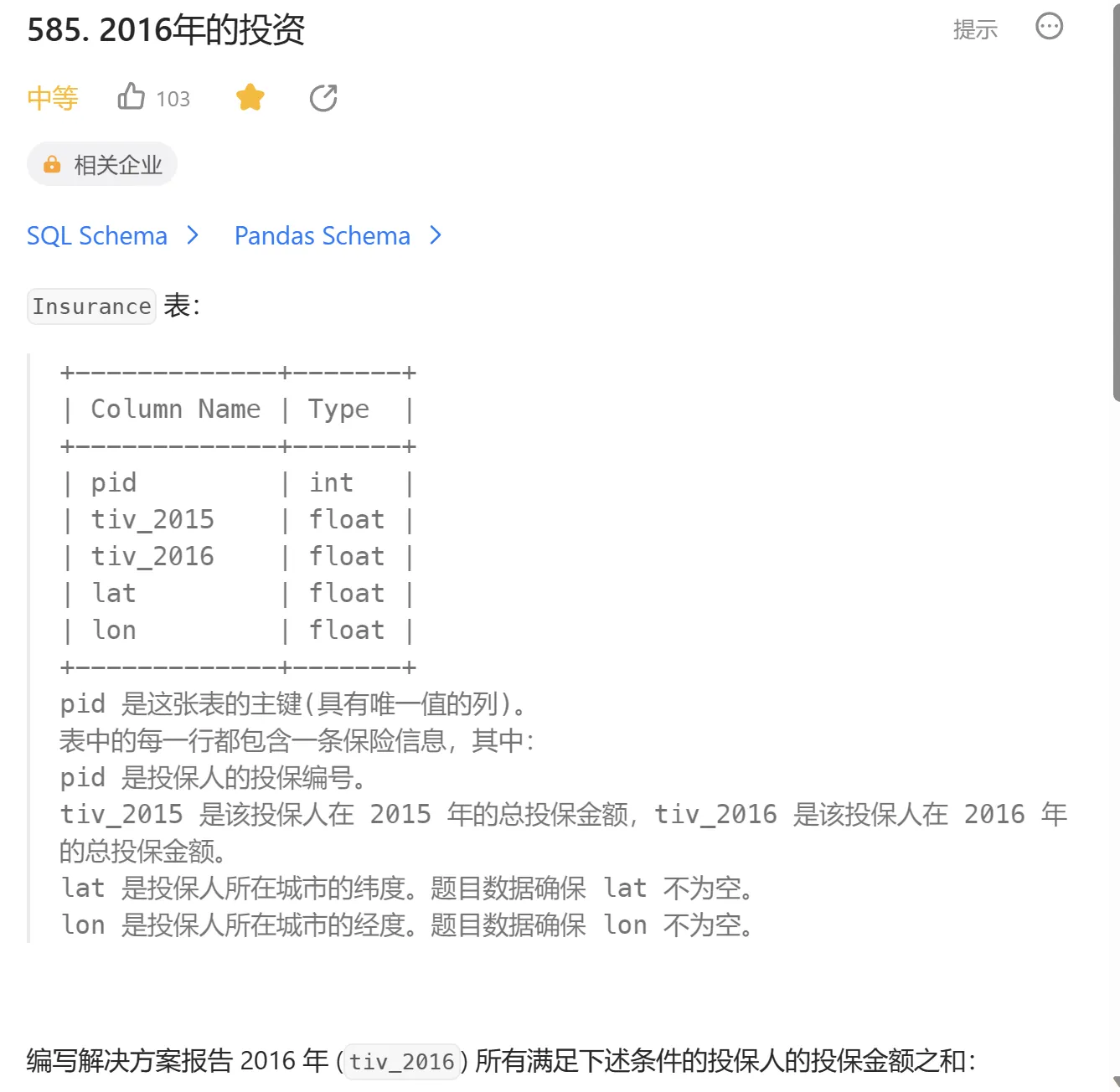
sql
-- 建表语句
CREATE TABLE Insurance (
pid INT PRIMARY KEY,
tiv_2015 FLOAT,
tiv_2016 FLOAT,
lat FLOAT,
lon FLOAT
);
-- 插入语句
INSERT INTO Insurance (pid, tiv_2015, tiv_2016, lat, lon) VALUES
(1, 10.0, 5.0, 10.0, 10.0),
(2, 20.0, 20.0, 20.0, 20.0),
(3, 10.0, 30.0, 20.0, 20.0),
(4, 10.0, 40.0, 40.0, 40.0);
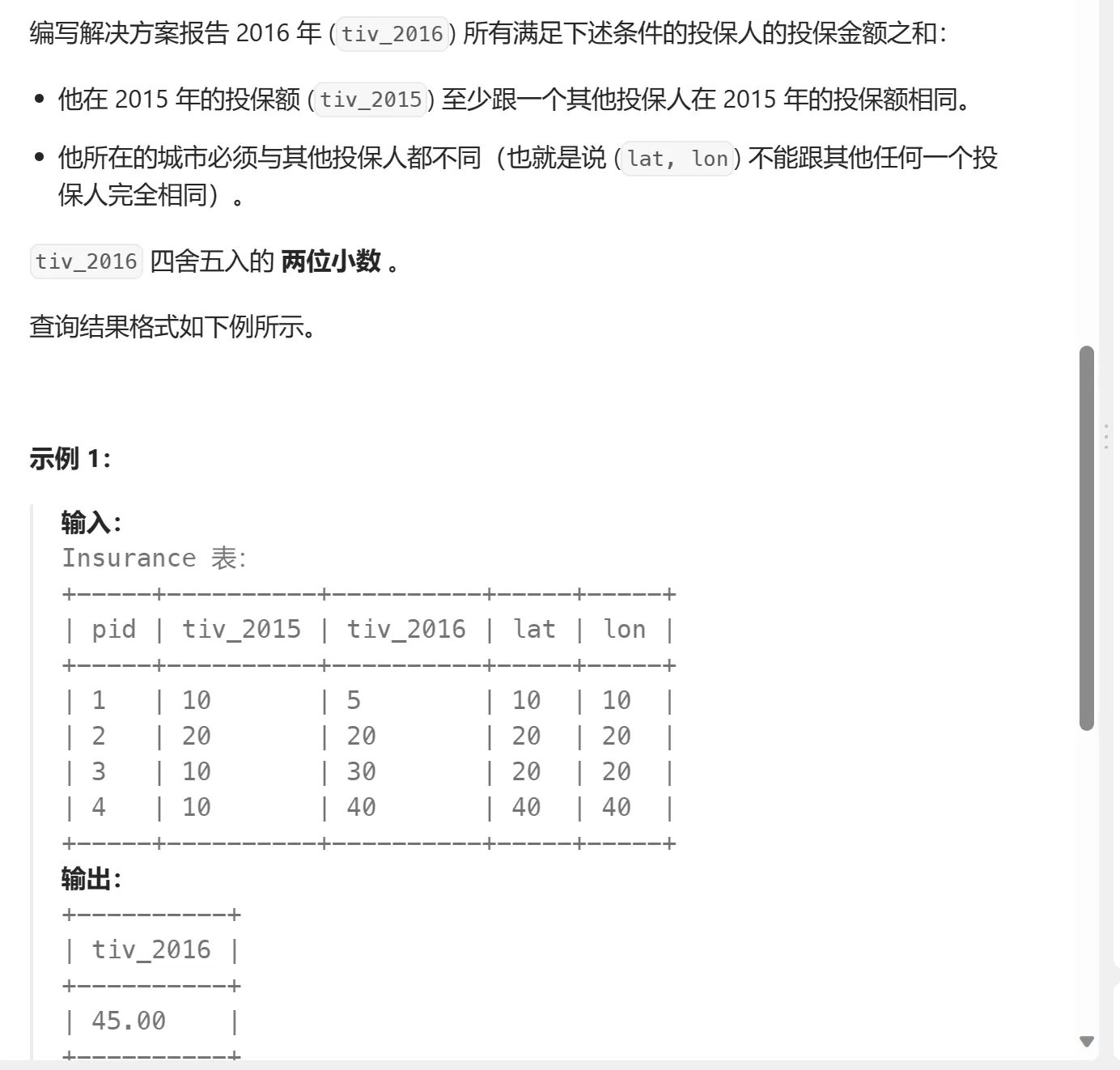
select * from Insurance;
SELECT ROUND(SUM(tiv_2016), 2) AS tiv_2016
FROM Insurance
WHERE tiv_2015 IN (
SELECT tiv_2015
FROM Insurance
GROUP BY tiv_2015
HAVING COUNT(*) > 1
)
AND (lat, lon) NOT IN (
SELECT lat, lon
FROM Insurance
GROUP BY lat, lon
HAVING COUNT(*) > 1
);
SELECT ROUND(SUM(i1.tiv_2016), 2) AS tiv_2016
FROM Insurance i1
JOIN (
SELECT tiv_2015
FROM Insurance
GROUP BY tiv_2015
HAVING COUNT(*) > 1
) i2 ON i1.tiv_2015 = i2.tiv_2015
LEFT JOIN (
SELECT lat, lon
FROM Insurance
GROUP BY lat, lon
HAVING COUNT(*) > 1
) i3 ON i1.lat = i3.lat AND i1.lon = i3.lon
WHERE i3.lat IS NULL;
简洁的答案。


sql-- 建表语句
CREATE TABLE Activities (
sell_date DATE,
product VARCHAR(255)
);
-- 插入语句
INSERT INTO Activities (sell_date, product) VALUES
('2020-05-30', 'Headphone'),
('2020-06-01', 'Pencil'),
('2020-06-02', 'Mask'),
('2020-05-30', 'Basketball'),
('2020-06-01', 'Bible'),
('2020-06-02', 'Mask'),
('2020-05-30', 'T-Shirt');
SELECT sell_date, COUNT(DISTINCT product) AS num_sold, GROUP_CONCAT(DISTINCT product ORDER BY product) AS products
FROM Activities
GROUP BY sell_date
ORDER BY sell_date;
这个查询使用了 GROUP BY 子句按 sell_date 对数据进行分组。COUNT(DISTINCT product) 计算每个日期销售的不同产品的数量。GROUP_CONCAT(DISTINCT product ORDER BY product) 将每个日期销售的不同产品按词典序排序,并用逗号分隔连接起来。
最后,通过 ORDER BY 子句按 sell_date 对结果进行排序。
执行查询后,将返回按 sell_date 排序的结果表,包含 sell_date、num_sold 和 products 列。
总结
GROUP_CONCAT 函数用于将一组值连接成一个字符串,并可以选择性地添加分隔符。下面是 GROUP_CONCAT 函数的使用示例:
假设有一个名为 "Products" 的表,包含以下数据:
+----+---------+-------+ | ID | Product | Price | +----+---------+-------+ | 1 | Apple | 2.5 | | 2 | Orange | 1.8 | | 3 | Banana | 0.9 | | 4 | Mango | 3.2 | +----+---------+-------+
- 基本用法:
sqlSELECT GROUP_CONCAT(Product) AS ProductList
FROM Products;
输出结果:
+-----------------------------+ | ProductList | +-----------------------------+ | Apple,Orange,Banana,Mango | +-----------------------------+
上述查询将 "Product" 列中的所有值连接成一个字符串,并使用逗号作为默认的分隔符。
- 指定分隔符:
sqlSELECT GROUP_CONCAT(Product SEPARATOR '; ') AS ProductList
FROM Products;
输出结果:
+---------------------------------+ | ProductList | +---------------------------------+ | Apple; Orange; Banana; Mango | +---------------------------------+
在上述查询中,我们使用 SEPARATOR 关键字指定分隔符为分号和空格。
- 排序和去重:
sqlSELECT GROUP_CONCAT(DISTINCT Product ORDER BY Product DESC) AS ProductList
FROM Products;
输出结果:
+-----------------------------+ | ProductList | +-----------------------------+ | Orange, Mango, Banana, Apple | +-----------------------------+
在上述查询中,我们使用 DISTINCT 关键字去除重复值,并使用 ORDER BY 子句按照降序对值进行排序。
- 设置最大连接长度:
sqlSET SESSION group_concat_max_len = 10000;
上述语句设置 group_concat_max_len 变量的值为 10000,以增加 GROUP_CONCAT 函数连接的最大长度。默认情况下,该变量的值为 1024。
注意:GROUP_CONCAT 函数的结果字符串长度受到 group_concat_max_len 变量和服务器的 SQL 模式限制。
本文作者:yowayimono
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录